Prise de décision adaptative
dans un habitat intelligent
RJCIA 2016
Alexis BRENON, François PORTET, Michel VACHER


Plan
- Ma thèse et son contexte
- Prise de décision dans les habitats intelligents
- Méthode et corpus
- Expérimentation
- Conclusion
Ma thèse et son contexte

- Projet Investissement d'Avenir
- Partenariat avec des industriels
- Développement d'un système intéractif vocal dans un habitat intelligent
- 1 an et demi de thèse
- Reconnaissance d'activité
- Interactions contextualisées
Adaptation à l'utilisateur lors d'interactions vocales
dans un habitat intelligent
dans un habitat intelligent
Prise de décision dans les habitats intelligents
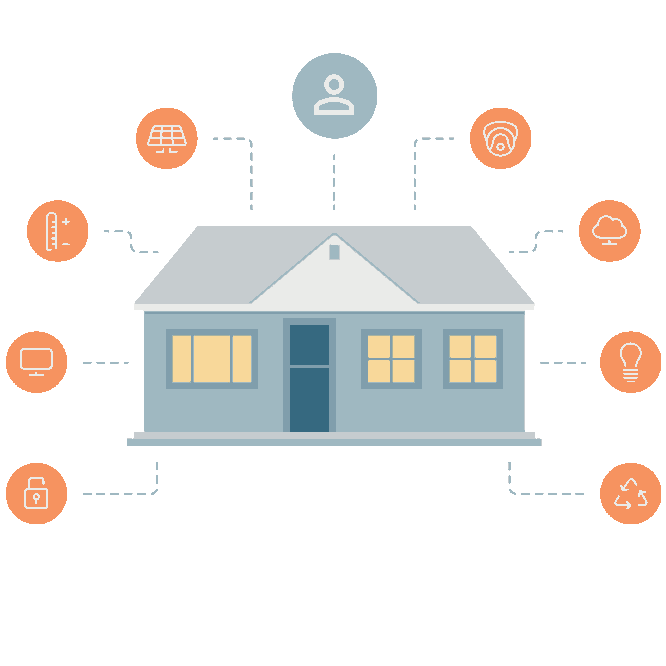
Home. Augmented
- Perception de l'environnement et actions
- Informatique ubiquitaire et intelligence ambiante
- Perception = contextualisation
- Détection d'évènements
- Adaptation des interactions
Jarvis, ouvre les volets !
-
Intérêt particulier pour les maisons intelligentes contrôlées par la voix
- Communication
naturelle
- Adapté aux :
- personnes à mobilité réduite
- situations d'urgences
- Communication
-
Problème d'ambiguïté des commandes
- Utilisation du contexte
État de l'art des systèmes de prise de décisions dans les habitats intelligents
-
Systèmes à base de règles :
- Logiques floue ou de description
- Modélisation simple
- [Kofler et al., 2012]
- Systèmes statistiques
- Réseaux bayésiens
- Prise en compte de l'incertitude
- [Lee et al., 2012]
Systèmes figés dans le temps
Peu de travaux sur l'adaptation aux changements d'habitudes
ou de comportements
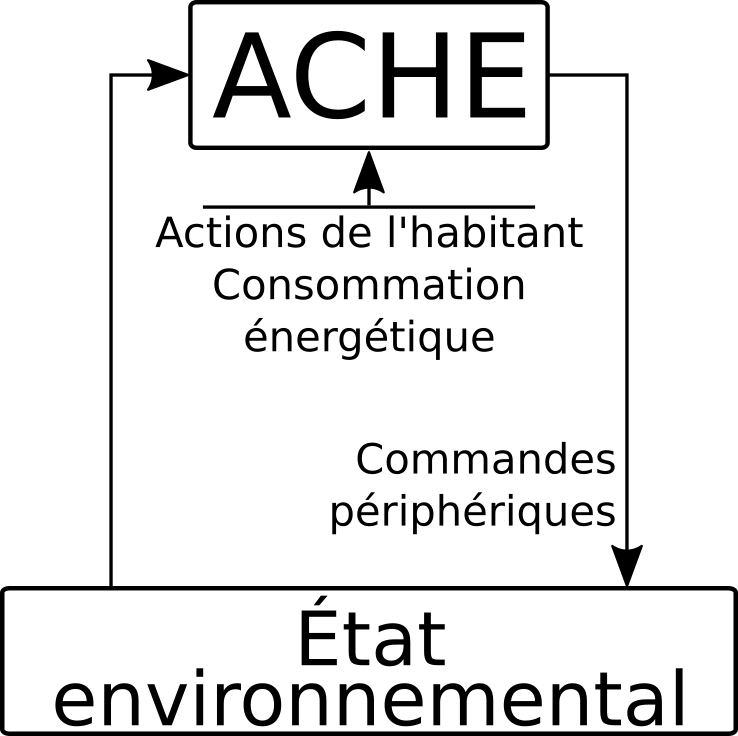
Un précurseur
- Le projet Adaptive House/Ache [Mozer, 1998] :
- Apprentissage à partir d'observations
- Mise à jour continue grâce aux mécanismes de l'apprentissage par renforcement
- Projet inactif à notre connaissance
Méthode et corpus
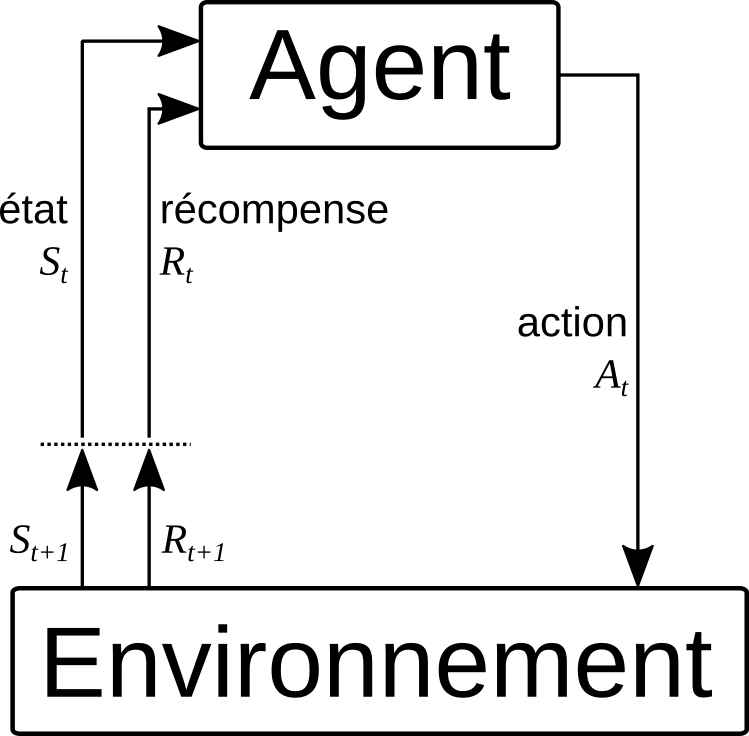
Apprentissage par renforcement
- Technique d'apprentissage automatique [Sutton et al., 2015]
- Interactions entre un agent et son environnement
- L'agent est récompensé à chaque étape
- L'agent doit maximiser sa récompense
- Extension des approches classiques : le \(Q\)-Learning
- [Watkins, 1989]
- Réduction du coût de calcul
- Représentation matricielle de la fontion de \(Q\)-Valeur
\( Q^{t+1}_{s_{t},a_{t}} = Q^{t}_{s_{t},a_{t}} + \alpha \left( r(s_t, a_t) + \gamma \max_{a_{t+1}} Q^{t}_{s_{t+1}, a_{t+1}} \right) \)
Exemple d'application
| \( a_0 \) Ouv. Volets Chambre |
\(a_1\) Ouv. Volets Armure |
\(a_2\) No-Op |
|
|
\(s_0\) Chute libre |
0 |
0
1
|
-100 |
|
\(s_1\) Tony est sain et sauf |
0 | 0 | 0 |
|
\(s_2\) Tony est décédé |
-100 | -100 | -100 |
\( Q^{t+1}_{s_0,a_1} = Q^{t}_{s_0,a_1} + \alpha \left( r(s_0, a_1) + \gamma \max_{a_{t+1}} Q^{t}_{s_1, a_{t+1}} \right) \)
\( = 0 + 1 \times \left( 1 + 0.25 \times 0 \right) = 1 \)
\( = 0 + 1 \times \left( 1 + 0.25 \times 0 \right) = 1 \)

Exemple d'application (cont.)
| \( a_0 \) Ouv. Volets Chambre |
\(a_1\) Ouv. Volets Armure |
\(a_2\) No-Op |
|
|
\(s_0\) Chute libre |
0
-26
|
0 | -100 |
|
\(s_1\) Tony est sain et sauf |
0 | 0 | 0 |
|
\(s_2\) Tony est décédé |
-100 | -100 | -100 |
\( Q^{t+1}_{s_0,a_0} = Q^{t}_{s_0,a_0} + \alpha \left( r(s_0, a_0) + \gamma \max_{a_{t+1}} Q^{t}_{s_2, a_{t+1}} \right) \)
\( = 0 + 1 \times \left( -1 + 0.25 \times -100 \right) = -26 \)
\( = 0 + 1 \times \left( -1 + 0.25 \times -100 \right) = -26 \)
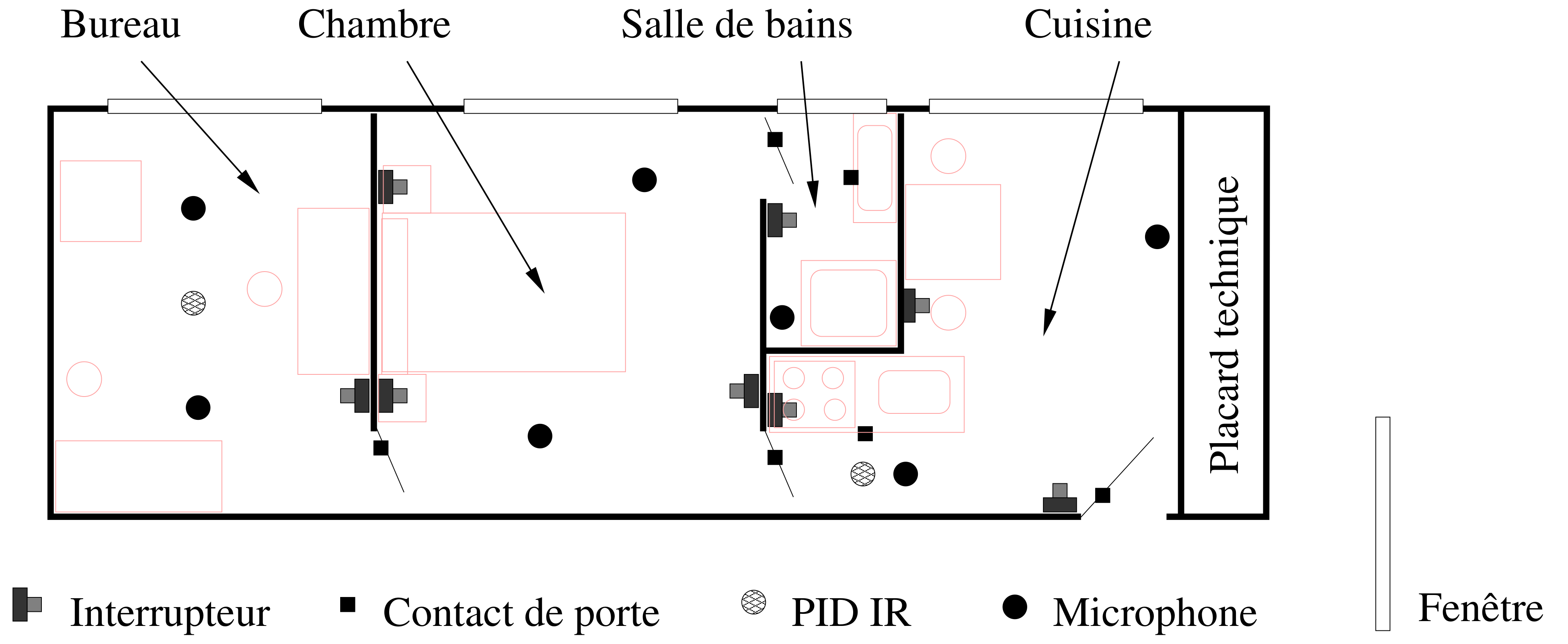
Domus
- Habitat intelligent conçu par le Laboratoire d'Informatique de Grenoble
- 30 m² comprenant une cuisine, une chambre, une salle de bain et un bureau
- Plus de 150 capteurs et actionneurs pour gérer l'éclairage, les volets, les médias, etc.
Le corpus d'interactions Sweet-Home
- Récolté dans Domus
- Disponible en ligne
[Chahuara et al., 2013] - 11 heures d'enregistrement
- 16 participants (7 , 9 )
- Scénario prédéfini à réaliser via des commandes vocales
- Demander la température
- Ouvrir les stores
- etc.

Expérimentation
Mise en forme des données
- Corpus Sweet-Home :
- 407 instances (\(\approx\) 25 par sujets)
- Non exhaustif (11% des états possibles)
- Corpus simulé :
- 380 instances
- Exhaustif mais non déterministe
blind - open kitchen none -> blind - open kitchen
light - on kitchen cook -> light - on kitchen - sink
Méthode d'apprentissage
- 324 états, 32 actions, poids initialisés uniformément
- Un état est fourni au système
- Le système sélectionne l'action la plus pertinente
- Action ayant le plus fort poids étant donné l'état
- L'action exécutée est comparée à l'action attendue
- Le système est récompensé
- Différentes fonctions de récompenses peuvent être utilisées
- Un nouvel état est fourni au système s'il a fait le bon choix
Résultat de l'apprentissage
- Création d'un modèle de base
- 100 000 interactions issues du corpus simulé
- Leave-One-Subject-Out Cross-Validation (LOSOCV)
- Adaptation du modèle
- Évaluation
- Chaque phase est décomposée en 10 étapes d'apprentissage (training epoch)

Évaluation
Mesure de la récompense moyenne obtenu lors de la suite d'interactions
- Différence expliquée par deux principaux facteurs
- Phase d'apprentissage très exploratoire
- Différence de taille de corpus

Évaluation (cont.)
Problème apparenté à de la classification de contexte
- Bon niveau de classification
- Précision \(\approx 70\,\%\)
- Rappel \(\approx 35\,\%\)
- Score F1 \(\approx 45\,\%\)
- Confusion entre actions similaires

Conclusion
Intérêts et limitations
- Lien entre les approches logiques et statistiques
- Adapté à des données discrètes ou événementielles
- Temps de convergence long
- Absense de prise en compte de l'incertitude
Et après ?
- Utilisation des processus de Markov partiellement observable (POMDP)
- Gestion de l'incertitude
- [Zaidenberg et al., 2011]
- Utilisation de réseaux de neurones
- Forte dynamique de recherche
- [Mnih et al., 2015]
Bibliographie (cont.)
- [Watkins, 1989] (1989). Learning from Delayed Rewards. PhD thesis, King's College.
- [Weiser, 1991] (1991). The computer for the 21st century. Scientific American, 265(3):66–75.
- [Zaidenberg et al., 2011] (2011). Reinforcement Learning of User Preferences for a Ubiquitous Personal Assistant. In Mellouk, Abdelhamid, editor, Advances in Reinforcement Learning, pages 59-80. Intech.